Field Notes from 2026-04-27. One customer ticket. One real bug. Six sites that had been silently degraded for as long as 76 days.
A customer opened a ticket this morning. Their WordPress backend was throwing this on save:
Redis encountered a fatal error: OOM command not allowed when used memory > 'maxmemory'That message is unambiguous if you have spent time with Redis. The
instance is full, and it is configured with the noeviction
policy, so writes are refused outright instead of older keys being
dropped. Five minutes of work to fix that one site. Eight hours of work
to fix what we found while we were in there.
Here is the chain.
The first site
Plesk's LiteSpeed Web Server extension provisions a per-user Redis
instance for every subscription that turns on object caching. By default
each instance is capped at 64 MB and ships with the upstream Redis
default eviction policy, noeviction. That default makes
sense for a general-purpose Redis used as a primary data store: you do
not want Redis throwing away your data unprompted. It is exactly the
wrong default for an object cache. An object cache is, by
definition, disposable. The whole point is that you can lose any entry
at any time and the application is fine.
For a busy site (in this case a high-traffic news site, hundreds of object writes per second under load) the instance filled up, and from that moment on every cache write returned the OOM error. Cache reads still worked, sort of, but writes were refused. WordPress dutifully logged the fatal in the admin notice area, the customer saw it, the customer wrote in.
The fix had two parts.
First, raise the cap. We bumped the per-user limit on the affected subscription from 64 MB to 256 MB. That bought headroom for the working set.
Second, change the eviction policy. LSWS supports per-user Redis
configuration overrides via a config file at
/usr/local/lsws/lsns/conf/redis.conf, applied through their
supported redis_user_action.sh configupd mechanism. We
deployed the file with one line that mattered:
maxmemory-policy allkeys-lruAfter that, Redis self-manages. When the cache fills up, it evicts the least-recently-used keys to make room for new ones. That is the correct behavior for an object cache. This is, by the way, a documented LSWS feature, it just is not the default. Worth noting if you run LSCache on Plesk.
Ticket closable. Customer happy. Then I pulled on a thread.
Pulling the thread
While I was looking at this customer's Redis service, I went to
spot-check a couple of other busy sites I knew were Redis-cached. I
expected to see active per-user Redis services. On one of them, there
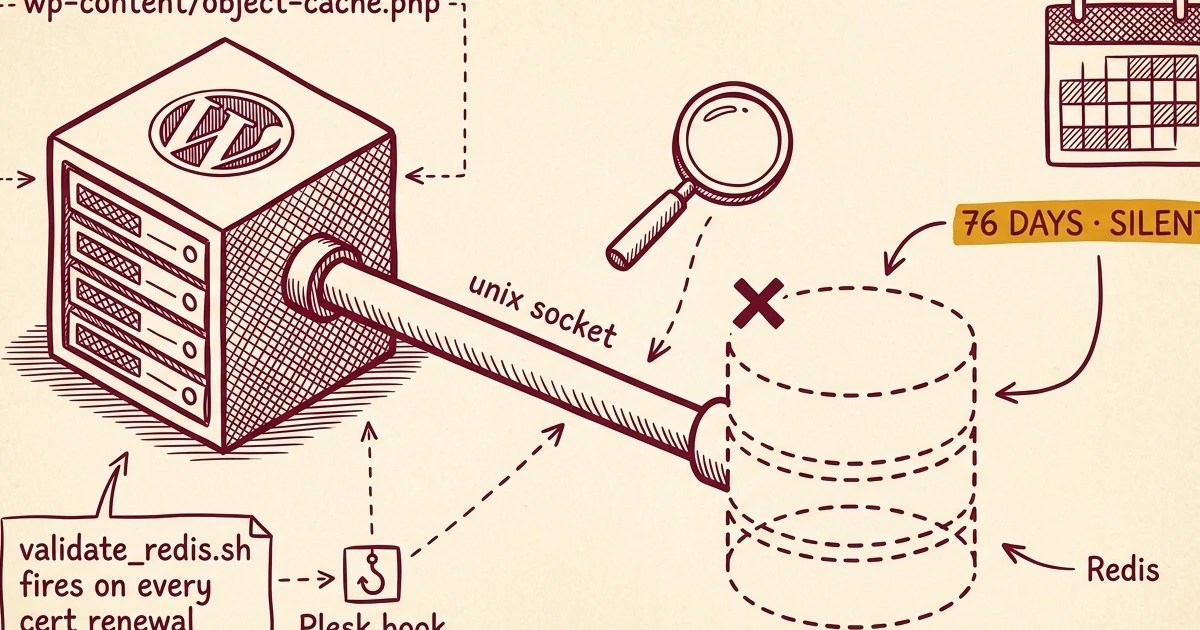
was nothing. No socket, no process, nothing. The site's
wp-content/object-cache.php dropin was still in place,
still pointing at a Unix socket that no longer existed. WordPress was
happily calling the dropin on every page load. Every
wp_cache_set() was returning false. Every
wp_cache_get() was a miss. None of this surfaced an error
to the site owner. The site simply ran slower than it should have,
hitting MariaDB on every request that should have been served from
cache.
That is the failure mode that bothers me. No error. No 500, no admin notice, no monitor trip. Just degraded performance, indefinitely.
I ran a fleet-wide audit. Six sites across three different servers were in this exact state. The earliest disable timestamp was 2026-02-10. That site had been running with its object cache silently broken for 76 days.
The root cause
The LSWS Plesk Extension installs a Plesk hook script called
validate_redis.sh. It registers itself for three Plesk
events: phys_hosting_create,
phys_hosting_delete, and phys_hosting_update.
The script's intent is reasonable: when a Plesk subscription is
genuinely deleted, tear down the per-user Redis service so we are not
leaking processes and sockets for users who no longer exist.
The condition it uses to detect deletion does not match how Plesk actually fires its hooks. Here is the disable condition, paraphrased to keep the snippet short:
if [ "${USER}" = "${OLD_SYSTEM_USER}" ] && [ "${NEW_SYSTEM_USER}" = "" ]; then
# tear down this user's Redis service
fiThe author's mental model: an empty NEW_SYSTEM_USER
means the user is being deleted, so it is safe to clean up.
The reality of how Plesk fires hooks: NEW_SYSTEM_USER is
empty whenever the user is unchanged. Plesk only populates that
variable when a subscription's system user is actually being switched.
If the subscription is being updated for any other reason (and there are
many other reasons), NEW_SYSTEM_USER is empty.
Many other reasons:
- Let's Encrypt certificate renewal, which fires every 60 days
- FTP password changes
- Mailbox creation, deletion, or password change
- PHP version changes
- Subscription plan changes
- Hosting parameters being touched in any way
Every routine subscription update, in other words, was tripping the
disable condition and tearing down that user's Redis service. The
webcachemgr log made this explicit. Each disable event was preceded by,
ten seconds earlier, a
Plesk hook, revalidating all packages line. The hook fires,
the script runs, the condition matches when it should not, and the Redis service
for an entirely innocent subscription gets torn down.
Site owners did not notice because, as I said, the failure was silent. The dropin file stayed in place. WordPress kept running. Just slower, by an amount that nobody had a baseline for.
Our fix
A small defensive patch to validate_redis.sh. Before
tearing down a user's Redis service, ask Plesk's authoritative database
whether the user actually still exists:
That is the entire patch. Routine updates skip the teardown, because
the user is still in sys_users. Genuine deletions still
tear down correctly, because by the time the post-delete hook fires, the
row is gone from sys_users. Tested both paths.
Then the cleanup work:
- Ran
redis_user_action.sh enablefor each of the six affected subscriptions to re-provision their Redis services - Deployed
/usr/local/lsws/lsns/conf/redis.confwithallkeys-lruto all six servers in the fleet, then ranconfigupdto apply, which bounced about 80 per-user Redis services fleet-wide. Brief cache rebuild on next page load, no user-facing impact - Wrote a fleet-wide audit script,
redis-users-audit.sh, that walks every WordPress install, checks for anobject-cache.phpdropin, and verifies that the Redis socket the dropin points at actually exists. We now run it as part of weekly maintenance
Filed upstream
validate_redis.sh tears down per-user Redis services on routine subscription updates because NEW_SYSTEM_USER is empty whenever the user is unchanged. Patched locally; engineering accepted the fix the same afternoon and uncovered a second related bug during their own validation.
We opened a ticket with LiteSpeed support, #194704,
on 2026-04-27 with the script analysis, the webcachemgr log evidence,
and the proposed patch. Until LiteSpeed ships the fix in the LSWS Plesk
Extension, the next extension upgrade will overwrite our local
validate_redis.sh patch. Our weekly maintenance now
includes a post-upgrade check that diffs the installed script against
our patched version and re-applies if it has been clobbered.
LiteSpeed engineering came back the same afternoon. The patch was
accepted ("your fix looks fabulous"), and during their own validation
they uncovered a second related bug they're now working on as part of
the same fix. They also acknowledged the broader concern with the
noeviction default. In their words: they hate that Redis
ships with noeviction as the default for object cache use
cases, lots of people complain about it, and they're thinking about
whether the LSWS Plesk Extension should include a default
redis.conf value out of the box rather than leaving it to
operators to discover. We may end up not needing to ship our own
redis.conf long term.
The non-deterministic redis_svc.sh content across our
six servers was also explained. Older Plesk Extension installs left some
local diff in place across version upgrades, which is why the script
differed slightly between our 2025-vintage servers and our 2024-vintage
ones. Newer installs converge to a consistent version. They considered the
differences acceptable since they never caused outages. Worth knowing
about if you are auditing fleet consistency.
If you run LSCache on Plesk, you have this bug right now. Worth checking.
Update: 2026-04-28
LiteSpeed engineering came back the next morning with a hybrid
candidate. Bob, their Redis and LiteSpeed Containers specialist, had
taken our patch into his own Plesk 18.0.77 Update 2 environment and
found that our plesk db | grep -q 1 SQL form did not work
there: different mysql-client behavior, different output. He swapped it
for a LOGIN_USER=... capture-and-compare and merged that
with our sys_users lookup intent. Same logical fix, more
portable form.
He also caught a separate bug we had not noticed. The script's
new-user-detection path test had an escaped-dot pattern that silently
failed on any Plesk system user with a dot in the login name. We have
several of those on one of our servers, accounts with domain-shaped
logins like capitacaribbean.com_k9o86dljex. Independently
caught in his validation pass, fixed in the same patch.
We canaried his hybrid on one server, ran the same simulation we used
for our original validation, and confirmed the spurious-update case is
correctly handled. Replied with one small stderr quoting fix (an
unquoted bash test that writes a harmless
[: =: unary operator expected to stderr on the
genuine-deletion path; behavior is correct, just noisy). He has the
candidate sitting in their next-release queue. We will update this post
when the official LSWS Plesk Extension upgrade lands and we can retire
our local patch.
Timeline
Earliest silent disable
Webcachemgr logs show the first per-user Redis service was torn down on a routine subscription update. No alert, no error in WordPress. The site simply began missing every cache call.
Silent fleet degradation
Six sites across three servers ran without working object cache. HTTP 200 on every request. MariaDB query rate climbed; nobody had a baseline to notice.
The break
A high-traffic news site fills its 64 MB Redis cap. Because noeviction is the default, the failure surfaces as a loud OOM error in the WordPress admin. Customer writes in.
Root cause + fleet audit + fix
Bad hook logic identified in validate_redis.sh. Fleet audit reveals the other five victims. Patch deployed, six services re-enabled, allkeys-lru rolled fleet-wide, audit script wired into weekly maintenance.
Filed upstream, accepted same-day
LiteSpeed ticket #194704 opened with the script analysis and proposed patch. Engineering replies within hours, accepts the fix, and uncovers a second related bug during their own validation.
Hybrid candidate from upstream
LiteSpeed engineering ships a hybrid candidate combining their independent diagnostic work with our patch. Canaried on one server; one small stderr quoting fix returned. Ready for inclusion in next LSWS Plesk Extension release.
What this taught us
A few things worth saying out loud, because they apply beyond this specific bug.
Silent failures are the dangerous ones. When a
system fails with an error, you fix it. When it fails
without one, you do not even know it is broken. The customer
who opened today's ticket actually got lucky: the OOM error surfaced
loudly because of noeviction, and that visibility is what
cracked the whole investigation open. The other six sites had no such
tell. Object cache misses do not crash anything, they just make every
page slower by some amount, and that amount is invisible unless you are
specifically watching for it.
Default configurations are not always good defaults.
Redis ships with noeviction because that is the safest
behavior for a general-purpose key-value store: refuse writes rather
than discard data the application might still need. For an object cache,
that is exactly inverted. Vendors who package Redis specifically as a
cache backend (LSCache, others) should ship with
allkeys-lru. Worth auditing, for any cache layer in your
stack, whether the defaults are written for your use case or
for someone else's.
One ticket can be a lens. The customer's ticket was about one site and one error message. The diagnostic chain ran through Plesk's hook system, the LSWS extension's installed scripts, Redis configuration defaults, the LSWS extension version-upgrade behavior, and Plesk's hook environment-variable semantics. We ended up shipping fleet-wide config changes, a patched hook script, an audit script, an upstream bug report, and a new weekly maintenance step. None of that work was on the calendar this morning. Treat individual symptoms as data points worth investigating, not just incidents to close.
Monitor at the layer where the failure actually is. Service-level monitoring would have shown all six of these sites as healthy. The WordPress page rendered. The HTTP status was 200. The site was "up" by every external measure. The failure was at a layer below that: does the per-user Redis socket actually exist for every site that has the LSCache object-cache dropin claiming to use it? That is the layer we now monitor. The general principle is: monitor at the layer of the failure, not at the layer of the symptom. If you only monitor symptoms, the silent failures will run for 76 days before someone notices.
File the bug report. Patch your fleet first, then file with the vendor. The Plesk LiteSpeed shops who do not catch this bug are running degraded right now and have no idea.
If your hosting setup uses LSCache and Plesk, here are three questions worth asking your host:
- Is your per-user Redis configured with
allkeys-lru, or is it still on the defaultnoeviction? - Do you monitor whether the Redis socket each site's dropin points at actually exists, or only whether the site responds with a 200?
- When was the last time you audited what your installed Plesk hooks are actually doing on subscription updates?
If those questions get blank stares, you may want to keep looking.

No comments yet. Be the first to comment!
Leave a Comment